Cacat Tersembunyi dalam Perlombaan AI “Semakin Besar Semakin Baik”
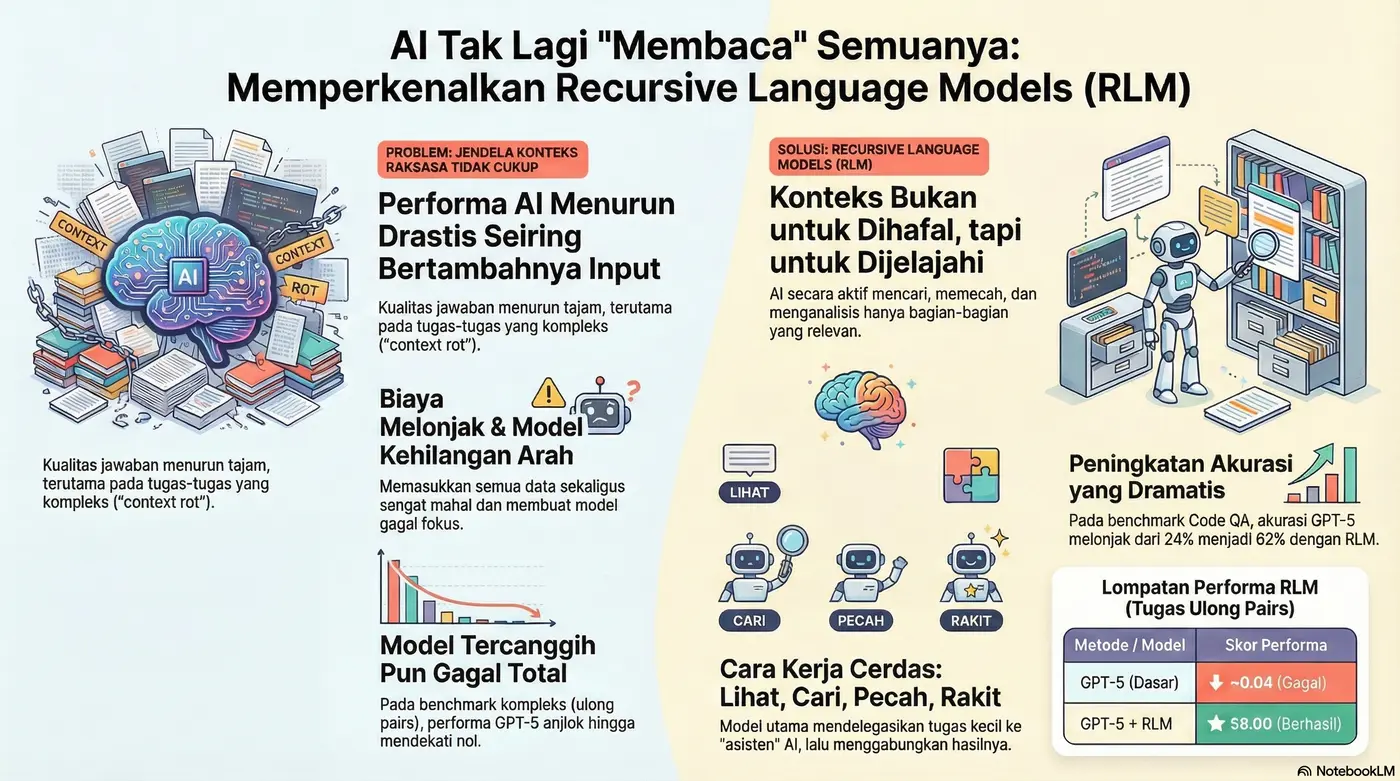
Selama beberapa tahun terakhir, kita telah menyaksikan perlombaan tanpa henti untuk memperbesar “jendela konteks” dalam model AI—dari 8.000 token menjadi 32.000, 100.000, hingga kini mencapai satu juta token. Logikanya tampak sederhana: semakin besar jendelanya, semakin pintar AI. Namun, pendekatan ini memiliki cacat fundamental yang tersembunyi. Seiring bertambahnya panjang input, kinerja justru menurun drastis, jawaban menjadi kabur, dan biaya membengkak. Fenomena ini, yang dikenal sebagai “pembusukan konteks” (context rot), telah menjadi tembok penghalang bagi kemajuan sejati.
Kini, sebuah pendekatan baru yang radikal dari MIT dan Prime Intellect tidak hanya menawarkan solusi, tetapi juga menantang seluruh trajektori industri AI saat ini. Ini bukan tentang model yang lebih besar atau jendela yang lebih lebar; ini adalah tentang mengubah secara total cara AI berinteraksi dengan informasi. Sebuah pergeseran paradigma yang siap mendefinisikan ulang batas kemampuan kecerdasan buatan.

1: Musuh Sebenarnya Bukan Ukuran Jendela, Melainkan “Pembusukan Konteks”
Masalah mendasar yang diabaikan oleh perlombaan jendela konteks adalah “pembusukan konteks”. Seiring bertambahnya panjang input, kualitas output model menurun drastis, terutama pada tugas-tugas yang kompleks. Tugas sederhana seperti menemukan frasa tertentu dalam dokumen besar mungkin masih bisa ditangani. Namun, untuk tugas yang memerlukan pemahaman hubungan antar berbagai bagian data, model AI canggih sekalipun akan gagal total.
Bahkan model sekelas GPT-5 pun runtuh saat dihadapkan pada tugas kuadratik seperti
ulong pairs, di mana ia harus membandingkan dan menggabungkan banyak entri secara berpasangan. Skor F1-nya anjlok mendekati nol jauh sebelum mencapai batas maksimum jendela konteks. Ini adalah bukti telak bahwa masalahnya bukan sekadar kurangnya ruang, tetapi bagaimana model memproses informasi dalam skala besar.2: Solusinya: Berhenti Menghafal, Mulai Menavigasi
Model Bahasa Rekursif (Recursive Language Models atau RLM) memperkenalkan perubahan paradigma fundamental. Alih-alih “menelan” seluruh buku ke dalam memori AI, teks tersebut ditempatkan di luar, seperti dokumen di atas meja. AI tidak lagi mencoba mengingat semuanya sekaligus. Sebaliknya, ia secara aktif berinteraksi dengan “dunia” eksternal ini. Prime Intellect mengambil konsep ini dan mengubahnya menjadi sistem konkret bernama RLMNV, yang menyediakan “ruang kerja” terstruktur bagi AI untuk beroperasi.
Proses “navigasi” ini berlangsung dalam beberapa langkah cerdas:
1. Melihat Sekilas: Model melakukan pemindaian cepat pada input untuk memahami jenisnya—apakah itu kode, log, atau tumpukan dokumen.
2. Mencari Secara Selektif: Alih-alih membaca semuanya, model mencari kata kunci dan pola yang relevan, mengabaikan sisanya.
3. Memecah Masalah: Untuk tugas yang kompleks, model memecah input besar menjadi potongan-potongan kecil yang dapat dikelola, sering kali menyerahkannya kepada AI pembantu yang lebih kecil.
4. Menyusun Jawaban: Setelah semua bagian yang relevan terkumpul, model merakit jawaban akhir secara bertahap.
4. Menyusun Jawaban: Setelah semua bagian yang relevan terkumpul, model merakit jawaban akhir secara bertahap.
Ukuran input berhenti menjadi batasan utama. Yang terpenting adalah seberapa pintar AI dalam menemukan jalannya melalui informasi.
3: Lompatan Performanya Hampir Tidak Bisa Dipercaya
Efektivitas pendekatan RLM terlihat jelas dari hasil benchmark yang begitu dramatis hingga sulit untuk diabaikan. Metode ini memungkinkan model untuk menyelesaikan tugas-tugas yang sebelumnya mustahil dikerjakan.
• Tanya Jawab Kode (LongBench V2): Akurasi GPT-5 melonjak dari 24% menjadi 62% dengan pengaturan RLM.
• Tugas Kuadratik (ulong pairs): Skor F1 GPT-5 melesat dari 0.04 (hampir tidak berguna) menjadi 58.00 dengan RLM penuh.
• Tugas Kuadratik (ulong pairs – Quen 3 coder): Model open-source ini mengalami lonjakan skor F1 dari di bawah 0.1 menjadi 23.11 dengan RLM penuh.
Ini bukan sekadar peningkatan inkremental; RLM memungkinkan model untuk menyelesaikan kelas masalah yang sebelumnya secara fundamental tidak terpecahkan dengan pendekatan tradisional. Terlebih lagi, pendekatan ini sangat efisien secara biaya. Satu kueri kompleks bisa memakan biaya hanya 1.50 hingga $3.00 untuk pendekatan konvensional—itu pun jika modelnya mampu menjalankannya.
Penting dicatat bahwa RLM adalah sebuah kerangka kerja; efektivitasnya masih bergantung pada “insting” dan kemampuan penalaran model dasar yang digunakan. GPT-5 dan Quen 3 coder, meskipun sama-sama meningkat, menunjukkan perilaku yang berbeda, membuktikan bahwa kualitas model inti tetap menjadi faktor kunci.
Takeaway 4: Terobosan Terbesarnya Bahkan Bukan pada “Rekursi”-nya
Salah satu temuan paling mengejutkan dari penelitian ini adalah bahwa komponen “rekursif”—kemampuan model untuk memanggil dirinya sendiri—bukanlah satu-satunya pendorong utama peningkatan kinerja. Dalam sebuah studi ablasi, para peneliti menguji versi yang lebih sederhana tanpa kemampuan melakukan panggilan rekursif (dikenal sebagai varian ‘ripple only‘, di mana model hanya mendapatkan ‘ruang kerja’ eksternal tanpa bisa memanggil dirinya sendiri).
Hasilnya luar biasa. Pada benchmark Tanya Jawab Kode, versi non-rekursif yang lebih sederhana ini mencapai akurasi 66%, bahkan sedikit lebih tinggi daripada versi RLM penuh. Pada tugas
ulong pairs yang sangat sulit, varian ini mencapai skor F1 43.93, sebuah lompatan kuantum dari skor dasar GPT-5 sebesar 0.04. Ini adalah sinyal kuat yang menunjukkan bahwa perubahan paling berdampak adalah memindahkan konteks dari dalam memori model ke lingkungan eksternal. Dengan tidak lagi terbebani untuk “membawa” semua informasi, model dapat bekerja jauh lebih efektif.Kesimpulan: Arah Baru untuk Kecerdasan Buatan
Selama ini, kemajuan AI identik dengan model yang lebih besar dan data pelatihan yang lebih banyak. Model Bahasa Rekursif (RLM) memperkenalkan dimensi baru: peningkatan pada saat inference atau saat model digunakan. Fokusnya bergeser dari seberapa banyak data yang bisa “dimuat” menjadi seberapa baik model dapat “bekerja melalui” informasi.
Pendekatan ini menghasilkan “jejak penalaran” (reasoning traces) yang dapat dianalisis. Di masa depan, jejak ini dapat dikumpulkan dan digunakan untuk melatih model menjadi navigator informasi yang lebih efisien, menciptakan siklus umpan balik positif. Ini membuka jalan bagi AI yang dapat menangani basis kode raksasa atau seluruh basis pengetahuan perusahaan tanpa kehilangan detail.
Hal ini memaksa kita untuk mengajukan pertanyaan fundamental yang bisa mengubah arah pengembangan AI ke depan:
Jadi, apakah ini akhir dari pentingnya jendela konteks?




Leave a Comment